Vertebrate Predicted Distribution Mapping
 |
|
Introduction
One of the major objectives of the National GAP Project is to document the representation of native vertebrate species in regional assesments. In order to meet this objective, we developed a spatial database of predicted species distributions throughout the state. While we don't have the resources to conduct a complete survey for every species, we do have access to a tremendous knowledge base that allows us to model distrubutions based on known range and habitat relationships. Currently the analysis includes terrestrial vertebrates, but the longterm goal is to expand the species of interest as time and resources allow.
The composition and structure of the dominant vegetation is an important and easily described measure of habitat for animals (Scott et al. 1993) and has long been used as an indirect indicator animal distributions (Austin 1991). Other biotic and abiotic factors (i.e. elevation, wetland type, and distance from standing water) can also play a major role in defining a particular species' habitat. Many studies of vertebrate species have been conducted over the years documenting this type of information. In addition, data on known ranges for vertebrate species has also been collected. This includes not only survey data records, but the cumulative field experiences of biologists who work with these species on a daily basis. If we take a habitat description, break it down into vegetative communities and other environmental factors (e.g. elevation, wetland type, etc.), and then identified those areas within a known range, we would be creating a predicted distribution map. That is essentially what we did for each terrestrial vertebrate species in North Carolina. The final step was to overlay those maps together to get a representation of biodiversity.
Why did we model only terrestrial vertebrates? Again, its a matter of resources. Realistically, we can only model a subset of all species. Terrestrial vertebrates are a logical choice because we generally know more about their habitat relationships and range extents than those of other taxa. Even so, there are over 400 terrestrial vertebrates modeled. The key to filling in the 'gaps' in the documented data is to have a thorough review by experts at every stage.
Making The List
The first step was to develop the list of species to be modeled. We used the following criteria to develop a list and then had our reviewers make arguments to either drop or add individual species.
| "Terrestrial vertebrates (birds, mammals, reptiles and amphibians) that are known to breed (5 of the last 10 years) and that are regularly occurring non-accidentals in the state of North Carolina." |
The result is a list of 414 species which include:
Known Ranges
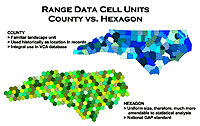
We used the Vertebrate Characterization Abstracts (VCA) as a starting point for developing known ranges. The VCA is a component of the Biological and Conservation Data System (BCD) developed by The Nature Conservancy and maintained by the North Carolina Natural Heritage Program in conjunction with the North Carolina Wildlife Resources Commission. It contains (among other things) occurrence data by county for each species in North Carolina. These data were developed from known occurrences and through review by knowlegeble experts. We took the county data and converted it to the EPA's EMAP hexagonal grid. There were several reasons for this. The hexagonal grid comprises of equal area cells (635 km) that are standardized for the entire nation which makes it much more desirable from a statistician's point of view. It is also the national GAP standard to facilitate regionalization of the final products. Take a closer look at Figure A for a better understanding.
FIGURE A:
Click on image to get a better view |
We are coding each hexagon with one of the following values for each species.
| 0 | Absent | No data confirming presence and not believed to occur except as accidental or migrant (<10%) |
| 1 | Possible | Possibility that species occurs (10%-80%) |
| 2 | Predicted | Species is predicted to occur (80%-95%) |
| 3 | Confirmed | Species is confidently assumed (>95%) or known to occur |
| 4 | Excluded | Originally coded as either predicted or confirmed, but is not believed to occur except as accidental or migrant |
| 5 | Historic | Species was know to occur prior to 1950 but has not been confirmed since, and is not believed to occur except as accidental or migrant (<10%) |
Developing these codes takes several steps for each species:
Habitat Relationships
To develop the habitat relationships we brought together information from a variety of sources, including TNC's Land Manager's Guide series, VCA habitat descriptions and individual journal articles. After creating a database that contains all that information, we went through each species and assigned an occurrence value (0/1) for each TNC vegetative alliance present in NC and other landuse/landcover types that exist in the NC-GAP Landcover map (i.e. urban, water, barren-sand, etc.). We also assigned values for other data types (i.e. elevation, wetland type, soil type, etc.) used to define suitable habitat.
Bringing It All Together - Distribution Modeling
Modeling distribution involves using a Geographic Information System (GIS) to process several layers of data for each species which include:
The simplest type of model is one where the species habitat is limited only by the known range and the type of vegetation utilized. However, even this simple model needs some extra processing steps to ensure that the output is a realistic representation of true distribution. Consider a species whose habitat includes agricultural fields. If the edge of the known range intersected a field, cutting the predicted distribution off in the middle of that field wouldn't make much sense. It would be more logical to predict the species presence for the entire field.
But what about a matrix of fields and/or other occupied vegetation types that are linked together and cross half the state? It makes even less sense to predict occurrence for the entire matrix when a large portion of it could lie well outside the known range. To get around this, we used a subwatershed data layer that; a) has boundaries based on natural features and b) has moderately sized partitions that would limit excessive areas outside the known range from being predicted as present.
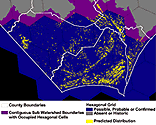
Figure B shows an illustration of subwatershed basins in the southeastern corner of the state along with how the known range of the Northern pine snake (Pituophis melanoleucus melanoleucus) is expanded for contiguous habitat polygons. Figure C illustrates the predicted distribution of the Northern pine snake for the same area. Notice how no habitat polygons (yellow) are present in the expanded range (purple) except for those that intersect some portion of the known range (blue).
FIGURE B:
Click on image to get a better view |
FIGURE C:
Click on image to get a better view |
The more complicated models used additional data layers to further filter what vegetation polygons are predicted as occupied. For example, suitable habitat for many amphibians depends on whether or not a body of water is nearby. To have this reflected in a model, we could limit what areas are predicted to be within a certain distance from a stream, inundated wetland or even vegetation types where vernal pools are known to occur.
After modeling each species, we then combined those maps together to develop maps of species diversity or richness. We then used these layers in conjunction with the Land Management data to help identify the 'gaps' in conservation.
Accuracy Assessment
Due to the limitation of funding and time, field-based studies to assess accuracy are impractical. However, we did compare high-confidence checklists from state parks and National wildlife refuges against what species are predicted to occur there. From this we developed error rates of omission and commission.